

Apache Druid is among the most popular open-source real-time solutions for Online Analytics Processing (OLAP). As pre-existing open-source databases like Relational Database Management System (RDBMS) and NoSQL were incapable of offering a low latency data ingestion and query platform for interactive applications, the need for Druid was stimulated.
Druid has been initially designed for problem-solving around ingesting and exploring large log data quantities. Apache Druid aims to quickly compute drill-downs and aggregate the data sets. Due to its features, Druid is being used by renowned brands like Netflix and Airbnb to run queries on data streams constituting billions of events per minute.
You might ask:
-
What is Apache Druid?
-
What is Apache Druid Architecture, and
-
Who can use Druid?
So, let’s get started with Apache Druid and give you all the answers you are looking for.
What is Apache Druid?
Apache Druid is a database that offers real-time analytics, developed for quick slice-and-dice analytics of OLAP queries on a large number of data sets. Druid is optimized for data analysis of time series (a sequence of data points indexed over time). The core design of Druid comprises the idea of time-series databases, data warehouses, and search systems. Apache Druid is commonly used for highly-concurrent APIs that require quick aggregations or GUIs of analytical applications as a database backend.
Some of the areas of common implementation for Apache Druid include:
-
Supply chain analytics
-
Advertising analytics
-
Web and mobile clickstream analysis
-
Application performance metrics
-
Server metric storage
-
Network telemetry analytics
Apache Druid Architecture
Apache Druid has a distributed multi-process architecture that is designed to be easy to operate and cloud-friendly. Every process type of Druid can be configured and scaled independently which gives high flexibility over the cluster. Some of the process types that Druid have are Coordinator (manages data availability), Overload (control data ingestion), Broker (handle external client’s queries), Router (route requests), Historical (store queryable data) and Middle Manager (ingest data).
One can deploy Druid processes into three server types, i.e., Master (to run coordinator and overload), Query (to run broker and router), and Data (to run historical and middle manager).
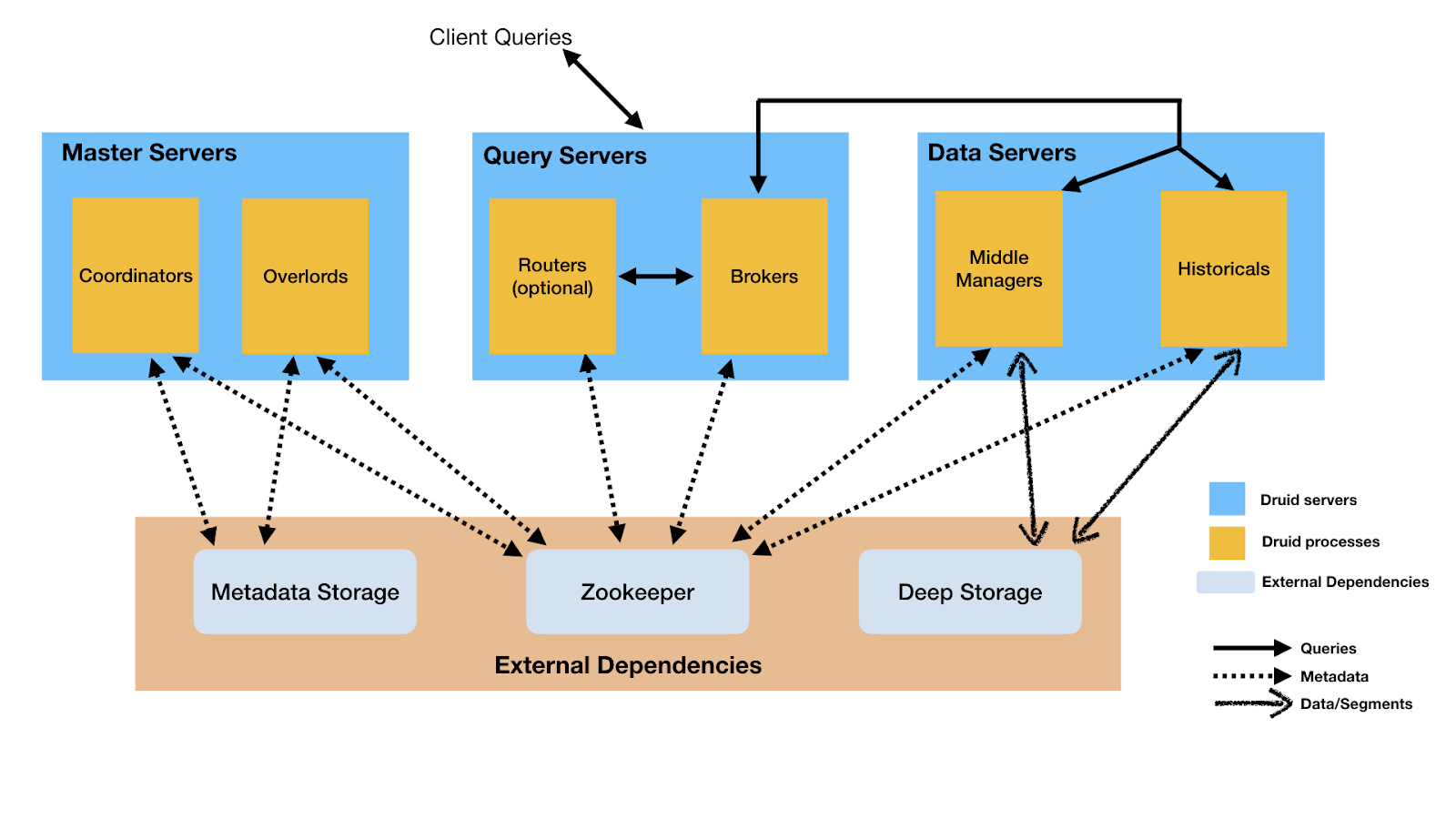
The above image shows how data and queries flow in Druid Architecture when we use Master/Query/Data server organization.
Apart from built-in processes, Druid has three external dependencies to leverage existing infrastructure. These external dependencies are Deep Storage, Metadata Storage, and Zookeeper.
Deep storage is an essential part of Druid’s elastic, fault-tolerant design. Deep storage is shared file storage used by Druid to store any data ingested into the system and can be accessed by every Druid server. Druid uses deep storage as data backup and as a way to transfer data between processes.
Metadata storage stores various shared system metadata like task information and segment usage information that is essential for Druid cluster’s working. While Zookeeper is used by Druid for management of cluster state. With Zookeeper it becomes easier to perform tasks like internal service coordination, discovery and leader election.
Key Features of Apache Druid
The key features of Apache Druid are as follows:
-
Scalable Distributed System
Data ingestion in Druid is done at the rate of millions of records per second. At the same time, Druid retains trillions of records while maintaining query latencies ranging from sub-seconds to a few seconds.
-
Columnar Storage Format
Column-oriented storage is used in Apache Druid so that it only loads the exact column required to conduct a query. The column storage format improves speed for queries, supports quick aggregations and scans.
-
Massive Parallel Processing
Druid facilitates processing every query parallelly across the complete cluster.
-
Realtime/Batch Ingestion
In Apache Druid, data can be ingested in real-time or in batches and becomes immediately available for query processing.
-
Cloud-native, fault-tolerant architecture
As Druid stores data copy in deep storage, it becomes easier to recover data even when all the Druid servers fail, making Apache Druid architecture fault-tolerant.
-
Time-based partitioning
Although you can implement additional partitioning of data based on the other fields, firstly, the data in Apache Druid is partitioned by time. The time-based queries in Druid only access the data partitions that match the query’s time range, improving query performance.
-
Self-balancing, Self-healing, and Easy to Operate
The cluster of Druid automatically re-balances itself without any downtime. That is, if a server fails, the system routes data around the damage in the server automatically so that server can be replaced.
-
Approximate Algorithms
For faster bounded memory usage, Druid includes algorithms for approximate ranking, approximate count-distinct, approximate quantiles and histograms. These algorithms are often faster than exact computations. However, when you require more accuracy than speed, you can use exact ranking and exact count-distinct algorithms.
-
Quick Filtering Indexes
To allow faster filtering and searching around multiple columns, Druid uses CONCISE or Roaring compressed bitmap indexes.
-
Automatic Ingest Time Summarization
Optionally, Druid supports data summarization at ingestion time that partially pre-aggregates data to reduce costing and boost performance.
When You Can Use Apache Druid?
With the understanding of Apache Druid architecture and features, it’s time to know where you can use it. If you have the following use cases then the chances of Druid being a choice for your project are high.
-
You mostly have aggregation, searching, scanning and reporting queries.
-
High data insert rates and fewer updates.
-
If you need query latencies between 100 ms and a few seconds.
-
The data you are using includes time components.
-
You need fast ranking and counting over high cardinality data columns like user IDs, and URLs.
-
You have two or more tables where each query hits a big distributed table.
-
You want the data to load from object storage like Amazon S3 or file distribution systems like HDFS, Kafka, flat files.
Conclusion
Druid is designed to empower applications that need up 24/7. Druid possesses several features that can ensure no data loss and system uptime. Apache Druid also offers data replication, automatic backups, independent services, and so much more to boost application performance.
So, if you too want to build an application and use the Apache Druid database for it, then hire developers who are well-versed in it.